队列任务/Spot 任务最佳实践
为了帮助客户在不同的计算场景下获得最佳的调度效率与成本收益,我们总结了以下队列管理以及 spot 任务的配置实践与指南。
1.单元运行时长
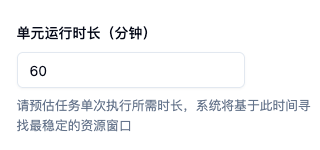
- 概念定义:针对 spot 任务设定的“最佳运行窗口”。
- 配置效果:平台根据集群资源的波峰波谷,提供了一个“抢占预测模型”,系统会根据此时长来将 spot 任务投放到合理的时间窗口中,来最大限度的降低该 spot 任务的抢占概率。
- 此字段的配置建议:
- 过短(如 5 分钟):可能会秒级拉起;但任务极易被频繁抢占打断。
- 过长(如 12 小时):运行连贯性好、不易被打断;但在算力高峰期极难拉起,任务容易长期卡在“排队等待中”。
2.独立任务 - 批量创建数
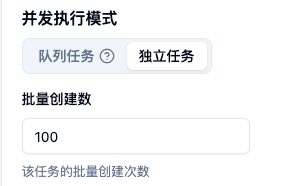
- 概念定义:在“独立任务”模式下,期望系统直接下发的完全独立的任务数量。
- 配置效果:若配置为 100,系统会在底层批量克隆出 100 个完全 K8s Job 并依次请求资源。这 100 个任务各自独立排队调度、独立计费,并且任务的资源镜像配置相同。
3.队列任务:组内任务总数
- 概念定义:在“队列任务”模式下,该任务组需要成功跑完的子任务总数量(可以理解对应 k8s 的 Completions)。
- 配置效果:若配置为 100,系统会将这 100 个任务打包为一个“任务组”投递至队列。队列引擎会负责监控,直到这 100 个子任务全部执行完毕,该任务组才算最终完结。
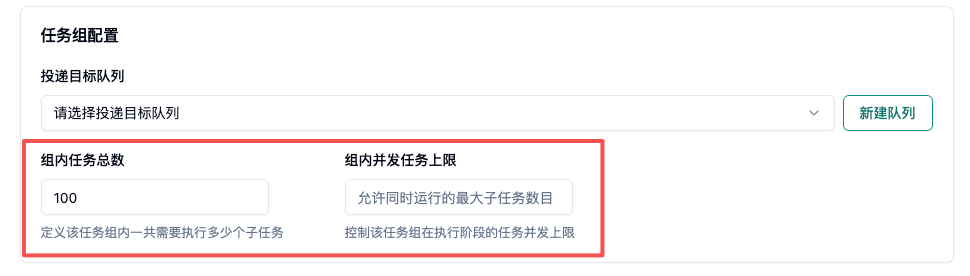
4.队列任务:组内并发任务上限
- 概念定义:在任务组内部,同一时间最多允许处于“运行中”状态的任务数量(可以理解对应 k8s 的 Parallelism)。
- 配置效果:若“任务总数”为 100,“并发上限”配置为 10,系统时刻只会维持 10 个任务。跑完一个,才会拉起第 11 个。
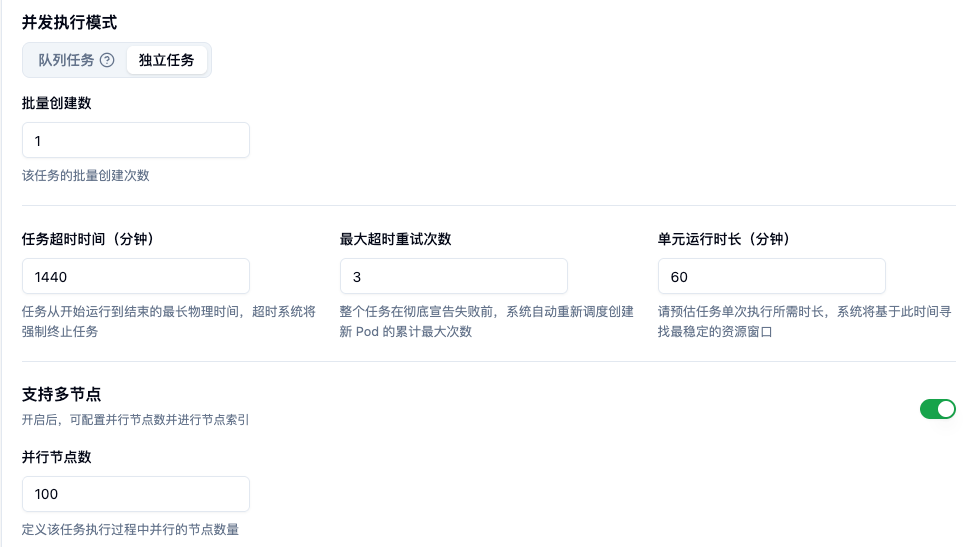
5.多节点开关
- 概念定义:决定当前任务是单节点运行,还是需要跨多台机器协同运算的分布式任务
- 配置效果:job 默认是单节点任务,开启此开关后,底层调度器将切换为 Gang 调度模式。系统必须同时凑齐所有需要的资源节点才会开始执行任务;否则任务会处于等待状态。
6.并行节点数
- 概念定义:指执行单个任务所必须需要的节点数量。
- 配置效果:若配置为 4,且当前是一个并发上限为 5 的队列任务组,那么该任务组的算力峰值将是 4 节点 × 5 并发 = 20 个物理节点。此参数直接决定了任务的资源需求体量。
二、1 个 100 节点任务 vs 100 个单节点任务
Section titled “二、1 个 100 节点任务 vs 100 个单节点任务”在配置发单表单时,很多开发者容易混淆“任务数”与“节点数”的关系。请看您的业务属于以下哪种情况,这决定了您该如何选择执行模式:
场景 A:100 个单节点任务(高并发零散任务)
Section titled “场景 A:100 个单节点任务(高并发零散任务)”-
特征:您有 100 份独立的数据需要处理,每份数据只需要 1 个节点。它们彼此独立,互不影响。
-
推荐模式:【队列任务】
-
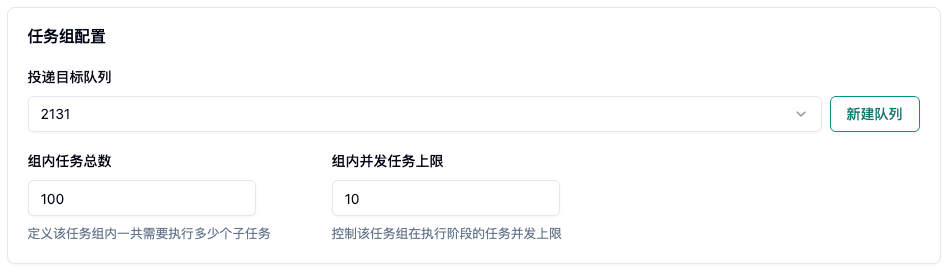
配置方式:
- 创建队列:队列容量填写 20(根据实际配额情况设置最大值)
- 任务总完成数:填写 100。
- 并行节点开关:关闭(即单节点任务)。
- 任务组内并发节点上限:填写 10(或根据实际情况填写)。
-
优势:
- 如果不走队列直接发 100 个独立的任务,难以批量对该任务进行生命周期管理。放进队列后,系统会时刻维持 10 个节点在跑,跑完一个补一个,直到 100 个任务平滑跑完。
- 并且会按照【队列】-【任务组】-【任务】-【节点】四级架构来查看管理
场景 B:1 个 100 节点任务(大规模分布式任务)
Section titled “场景 B:1 个 100 节点任务(大规模分布式任务)”-
特征:您需要训练一个庞大的模型,必须 同时拉起 100 个节点
-
推荐模式:【独立任务】 (或确保队列有极大空闲容量时的【队列任务】)
-
配置方式:
- 任务总完成数 (单体实例数):填写 1。
- 单任务节点数量(勾选支持多节点):填写 100。
-
特征:独立任务会直接向集群一次性请求全量节点资源。
三、其他业务场景的推荐配置
Section titled “三、其他业务场景的推荐配置”针对日常使用的痛点,我们推荐以下配置方式:
场景一:海量低优计算(如:海量数据清洗、离线批量处理)
Section titled “场景一:海量低优计算(如:海量数据清洗、离线批量处理)”👉 最佳组合:【队列任务】 + 【抢占式计费 (Spot)】
场景痛点:有很多任务要跑,但需要控制成本发 spot 任务,对完成时间没有极高要求。如果瞬间发海量 spot,很难调度起来。
解决思路:利用队列调度对大量任务进行管理,结合 Spot 实例的低价特性。即便遇到资源紧缺,任务也会在后台排队,有空闲卡时自动恢复。
💡 关键配置:
- 创建队列,根据实际情况设置队列节点上限。
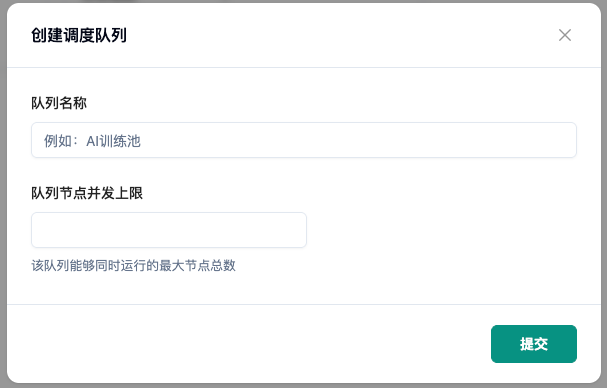
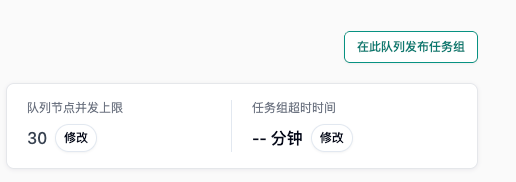
- 在队列中创建任务组
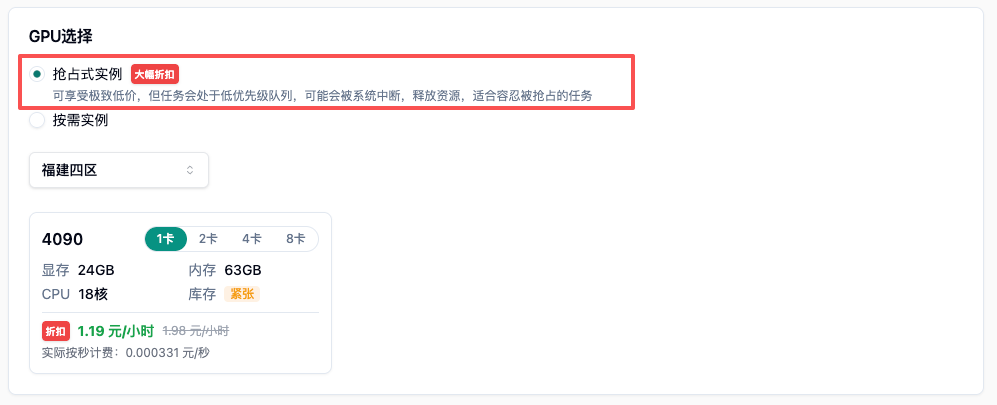
- 选择抢占式实例(即 spot 任务)
- 然后选择集群和卡型,库存紧张代表此时资源相对紧缺,库存充足代表该资源相对充足,容易调度。
- 接下来配置任务镜像
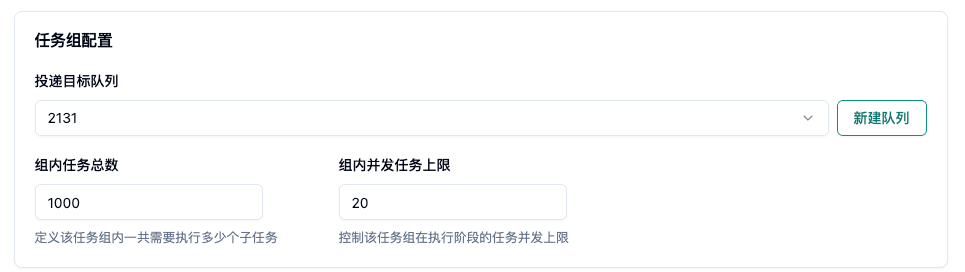
- 任务总完成数 :填入总批次数(如 1000)。
- 组内并发任务上限:填入期望同时运行的数量(如 20)。
- 多节点开关:关闭,代表该任务是单节点任务
- 代表往队列发了 1000 个单节点任务,同一时间最多启动 20 个任务
场景二:需要稳定保障的分布式大任务(如:重要模型训练)
Section titled “场景二:需要稳定保障的分布式大任务(如:重要模型训练)”👉 最佳组合:【队列任务】 + 【按量计费 (On-Demand)】
场景痛点:需要发布多个重要训练任务,每一个任务都不能被中断,且需要长时间按顺序执行。如果使用抢占式,中途被回收会导致全部白跑;
解决思路:使用按量实例保障资源不被回收,同时丢入队列进行管理
💡 关键配置:
- 选择按需实例(即 on-demand 任务)
- 支持多节点:开启,并且并行节点数 填入 8(指单个任务需要 8 卡)。
- 组内任务总数和并发任务上限:按照实际情况填写
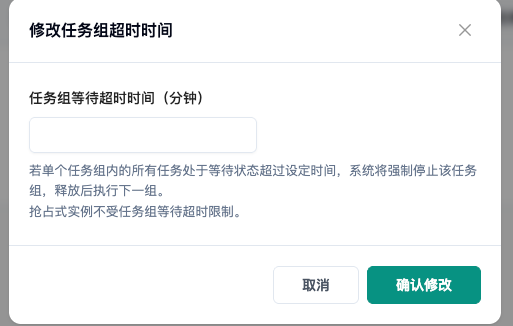
- 任务组异常终止超时时间:建议在创建该队列时,务必开启超时保护(如设置 60 分钟)。因为按量计费任务如果在遇到了异常或其他原因,整个任务组一直处于排队中。开启超时保护后,系统会自动停止卡死的任务组,让出队列通道给下一个任务。
场景三:日常零散的算法调试与实验
Section titled “场景三:日常零散的算法调试与实验”👉 最佳组合:【独立任务】 + 【抢占式计费 (Spot)】
场景痛点:算法工程师只想随便跑 3~5 个参数不同的对比实验脚本,不想在队列里排队。
解决思路:直接裸发 Spot 独立任务。系统会绕过队列,直接向集群发布调度。
💡 关键配置:
- 并发执行模式:选择 独立任务。
- 任务总完成数 (单体实例数):填写 5。
- 效果预期:系统直接为您创建 5 条的任务记录。