Job 批处理最佳实践文档
本文档基于共绩算力平台的真实操作数据撰写,覆盖 Job 批处理从资源选型、任务创建、并发执行到日志排查的全生命周期,帮助您以最低成本、最高效率完成 AI 训练与批量计算任务。
一、产品概述
Section titled “一、产品概述”Job 批处理是共绩算力平台为 AI 训练、推理和大规模数据处理场景量身定制的弹性计算服务。与传统的常驻实例(如云主机)不同,Job 批处理专注于”任务驱动”的计算模式------用户只需定义任务目标、所需资源和执行环境,系统将自动分配算力,并在任务完成后自动释放资源,从而最大化资源利用率并显著降低计算成本。
二、计费模式选型
Section titled “二、计费模式选型”Job 批处理提供两种计费模式,适应不同时效性和成本敏感度的需求。
按量计费:对执行时间有严格要求、不可中断的关键任务 资源保障度高,按秒精确计费,任务期间不会被回收 成本相对较高 抢占式计费: 容错率高、支持断点续训的 AI 训练或大规模批量处理 成本极低(通常为按量计费的数分之一)平台资源紧张时实例可能被主动回收
最佳实践: 对于支持 Checkpoint(检查点)的深度学习训练任务,强烈建议使用抢占式计费。通过合理配置保存频率,即使任务被回收,也能在重新调度后从最近检查点恢复,在保障任务进度的同时最大化成本效益。
三、创建 Job 批处理:全功能配置详解
Section titled “三、创建 Job 批处理:全功能配置详解”3.1 GPU 型号与资源选择
Section titled “3.1 GPU 型号与资源选择”平台提供了从推理卡(如 L40S、4090)到顶级训练卡(如 H800、A800)的丰富选择,支持 1 卡、2 卡、4 卡、8 卡配置。系统会自动展示所选配置对应的显存、内存、CPU 核心数、当前库存及计费详情。
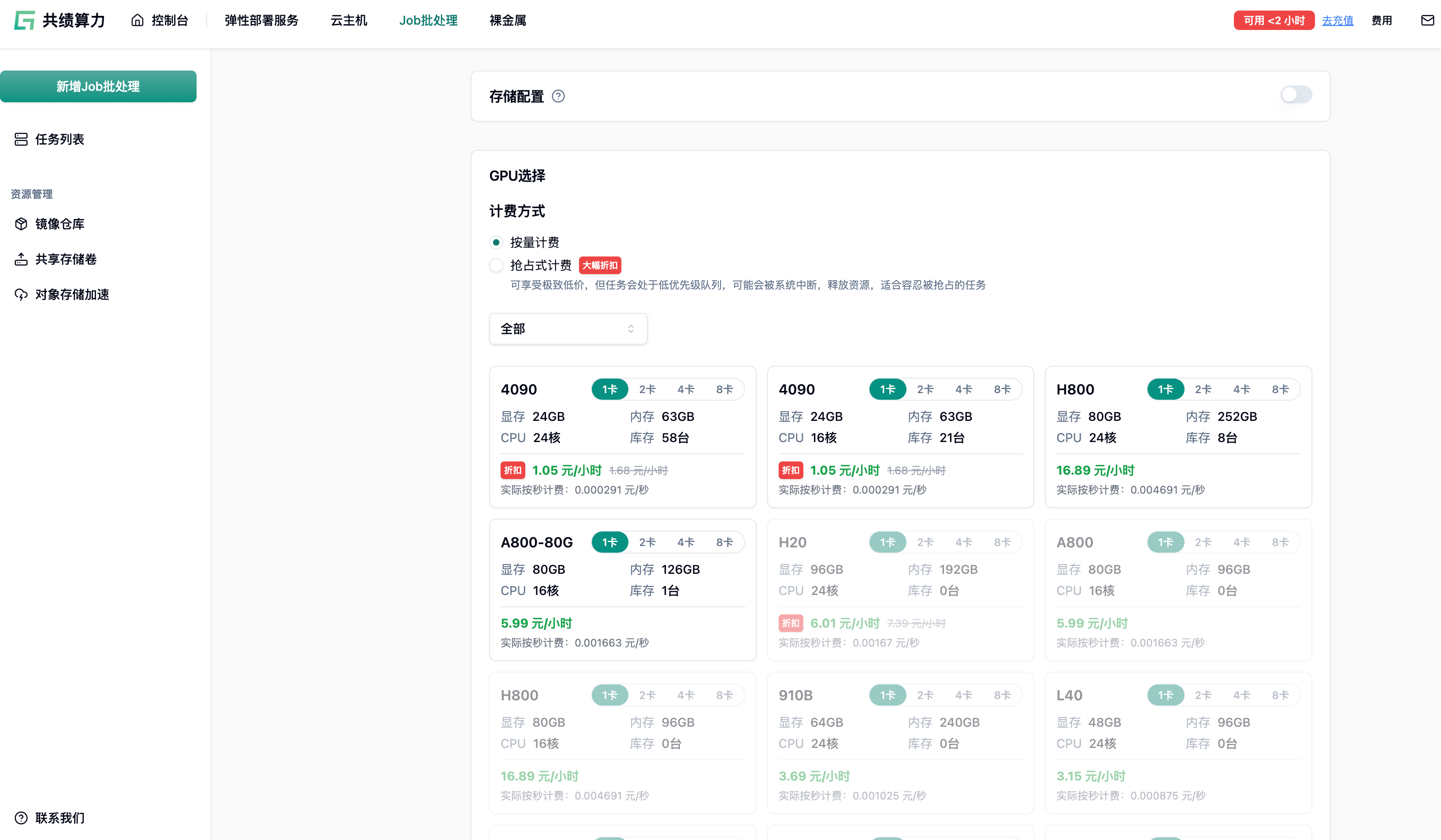
最佳实践: 优先根据模型参数量和 Batch Size 预估显存需求。推理任务通常单卡 4090 或 L40S 即可满足;大规模分布式训练建议选择 8 卡 A800 或 H800,以获得最佳的性能。
3.2 存储配置:数据的高效流转
Section titled “3.2 存储配置:数据的高效流转”存储是批处理任务的命脉。平台提供三种不同层级的存储方案,满足多样化的数据读写需求。
对象存储加速: 将 S3/OSS 等对象存储桶挂载到容器指定目录,提供只读访问 挂载大规模预训练模型权重、公开数据集,实现”秒级冷启动” 共享存储卷: 基于文件系统的持久化存储,支持多节点读写 存放训练代码、任务输出结果、模型 Checkpoint emptyDir 临时存储:容器生命周期内的临时磁盘空间,Pod 销毁后数据清除 同一 Pod 内多容器间的数据交换,或作为高速临时缓存
最佳实践: 采用”读写分离”策略。将庞大的数据集和预训练模型通过对象存储加速只读挂载,将训练过程中产生的日志和 Checkpoint 写入共享存储卷,以获得最佳的 I/O 性能和数据安全性。
3.3 镜像与运行环境配置
Section titled “3.3 镜像与运行环境配置”镜像是任务执行的基石。平台支持从官方仓库、社区仓库以及私有仓库拉取镜像。
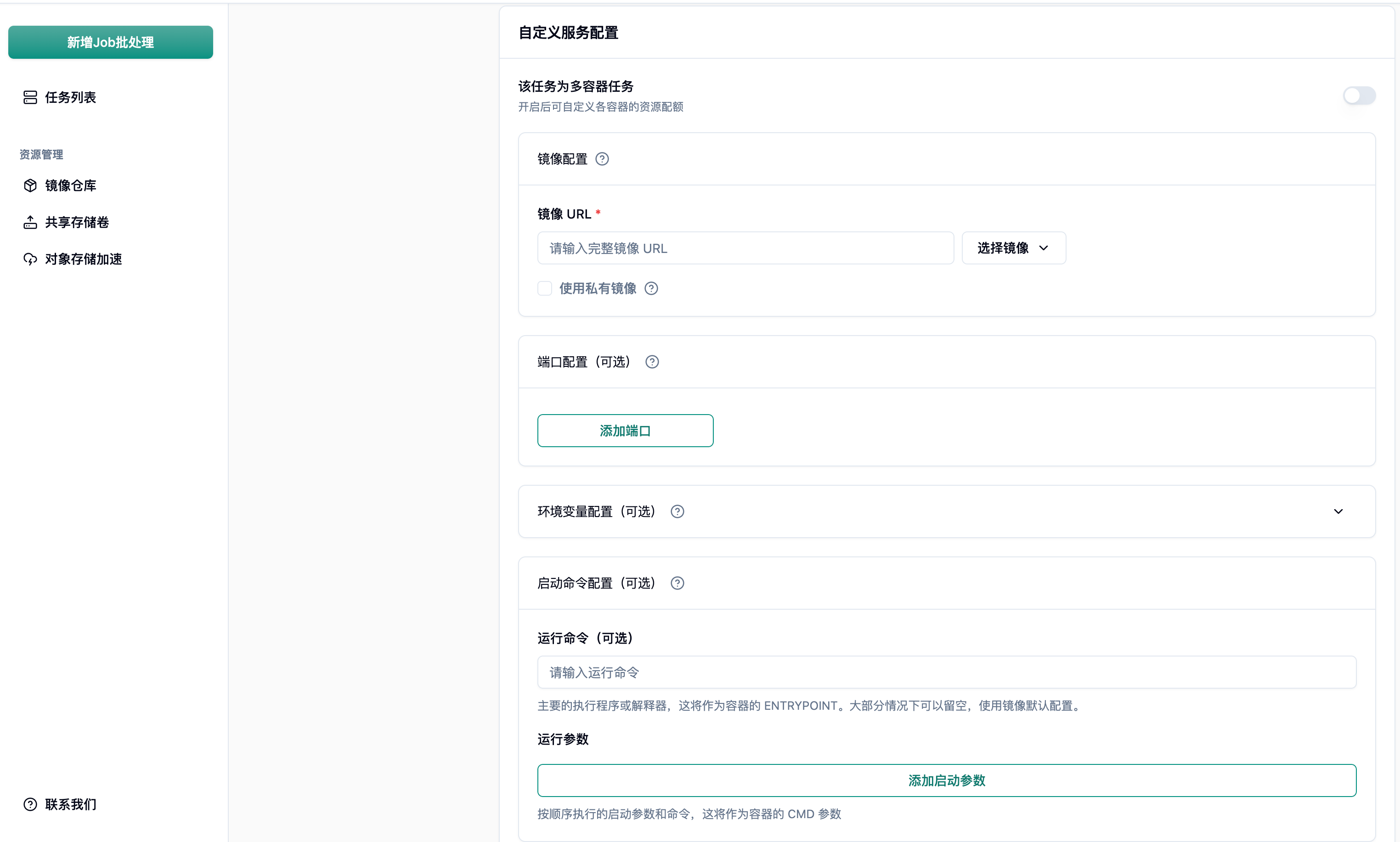
配置项说明:
- 任务名称: 建议使用有意义的命名规范(如
项目名-任务类型-日期),便于在任务列表中快速检索。 - 镜像地址: 填入容器镜像地址(如
harbor.suanleme.cn/bala/job-taskdemonstration:v1)。 - 环境变量: 支持
KEY=value或 JSON 格式,用于传递 API 密钥、配置参数等动态信息。 - 运行命令(ENTRYPOINT): 容器启动时执行的主程序(如
/bin/bash、python)。 - 运行参数(CMD): 传递给运行命令的具体参数(如
train.py --batch_size 32)。
最佳实践:
将可变参数提取为环境变量,保持镜像的纯粹性和可复用性。强烈建议使用平台内网镜像仓库(harbor.suanleme.cn),避免因公网访问限制导致镜像拉取失败。实测内网镜像拉取耗时仅需3.493 秒(30MB 镜像),而公网镜像(如docker.io/nvidia/cuda)可能因 403 限制直接失败。
3.4 任务策略与并发控制
Section titled “3.4 任务策略与并发控制”任务策略决定了系统如何调度和管理您的批处理任务。
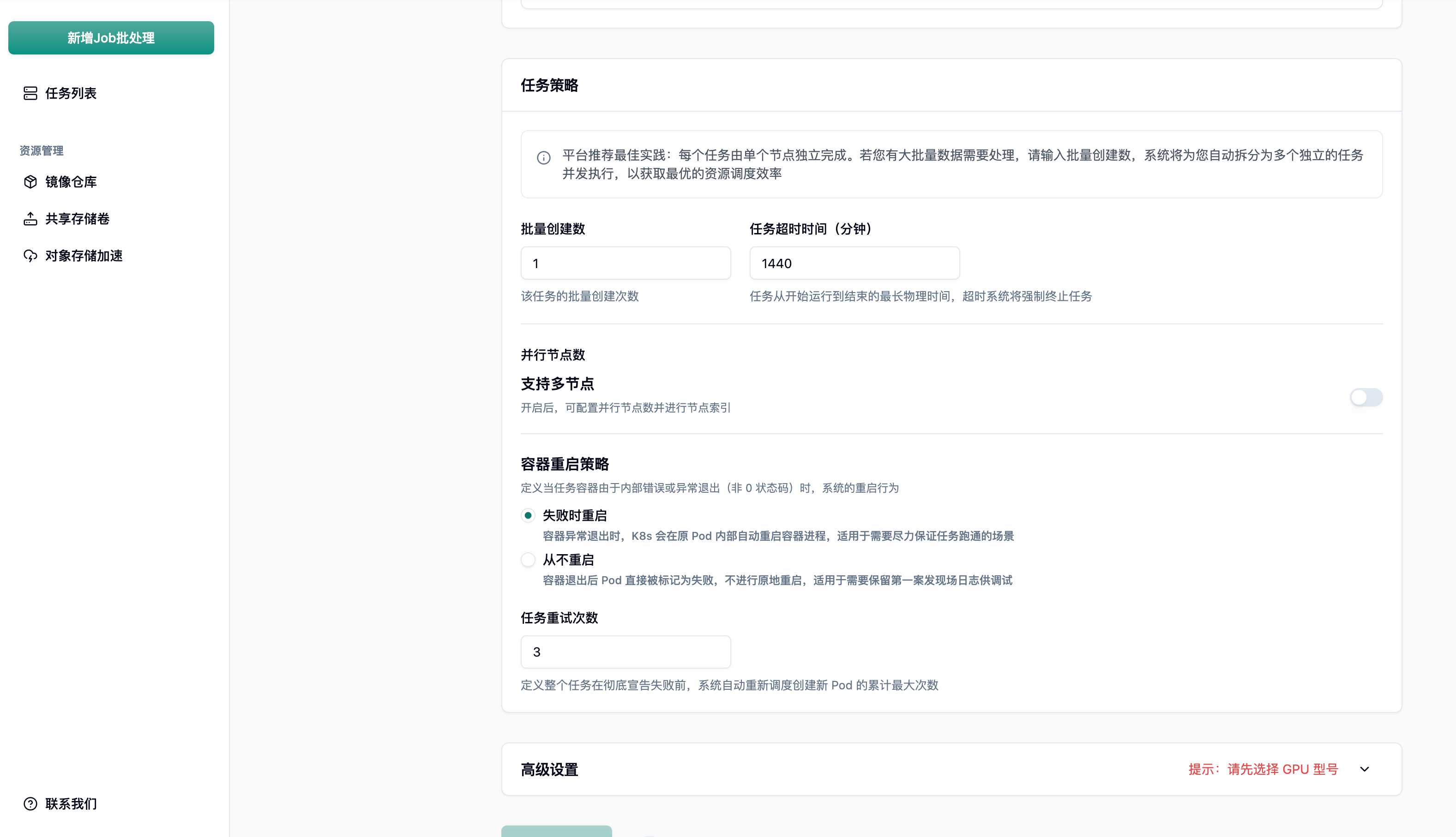
配置项说明:
- 批量创建数: 当有大量同质化任务时,直接输入批量创建数,系统会自动拆分为多个独立任务并发执行。
- 任务超时时间: 设定任务的最长物理运行时间(默认 1440 分钟)。超时后系统将强制终止任务,防止因死锁导致的资源浪费。
- 并行节点数: 定义任务执行过程中并行的节点数量(需开启”支持多节点”)。
- 节点索引:
开启后,系统为每个并行节点分配固定的独立索引编号(环境变量
JOB_COMPLETION_INDEX),容器内程序可通过该变量感知自身角色,实现数据分片或分布式协调。
最佳实践: 对于数据清洗或批量推理等完全并行任务,利用批量创建数或多节点 + 节点索引功能,可以成百上千倍地缩短总处理时间。务必设置合理的任务超时时间作为安全防线。
3.5 多节点分布式任务配置
Section titled “3.5 多节点分布式任务配置”开启”支持多节点”后,可配置并行节点数和节点索引,实现真正的分布式计算。
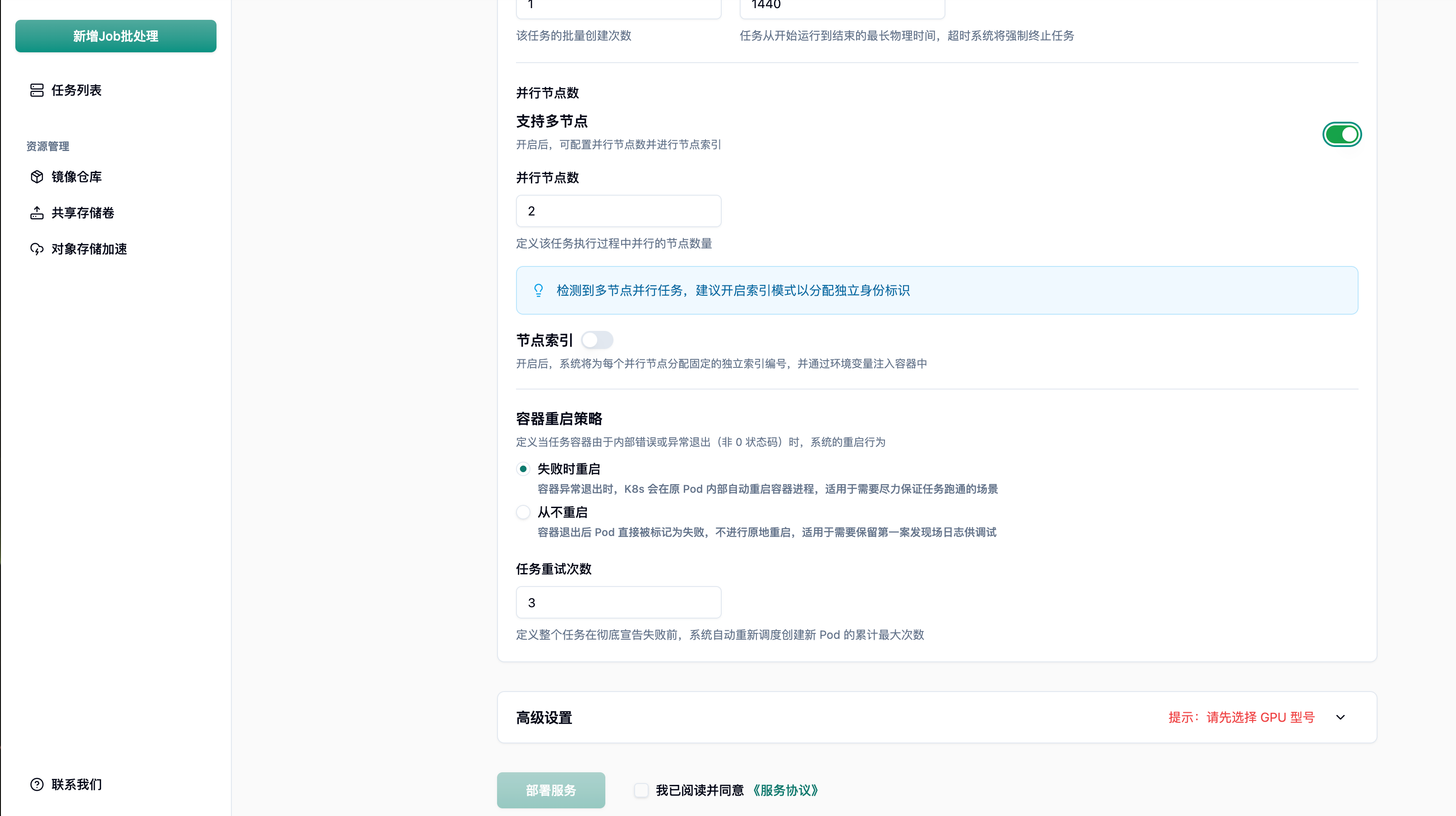
最佳实践: 在分布式训练场景(如 PyTorchDDP、DeepSpeed)中,结合节点索引环境变量 JOB_COMPLETION_INDEX区分主节点(rank 0)和工作节点,实现梯度同步和模型聚合。
3.6 容错与高可用设置
Section titled “3.6 容错与高可用设置”批处理任务通常运行时间较长,容错机制至关重要。
容器重启策略:
- 失败时重启(OnFailure): 容器异常退出时,K8s 会在原 Pod 内自动重启容器进程。适用于需要尽力保证任务跑通的场景。
- 从不重启(Never): 容器退出后 Pod 直接被标记为失败,不进行原地重启。适用于需要保留”第一案发现场”日志供调试的场景。
任务重试次数: 定义整个任务在彻底宣告失败前,系统自动重新调度创建新 Pod 的累计最大次数(默认 3 次)。
最佳实践: 代码调试阶段建议选择从不重启并配合较低的重试次数,以便快速定位问题。生产环境特别是使用抢占式实例时,建议选择失败时重启并增加重试次数,配合 Checkpoint 机制实现任务的自动恢复。
3.7 高级设置与性能调优
Section titled “3.7 高级设置与性能调优”高级设置提供了更底层的资源控制选项。
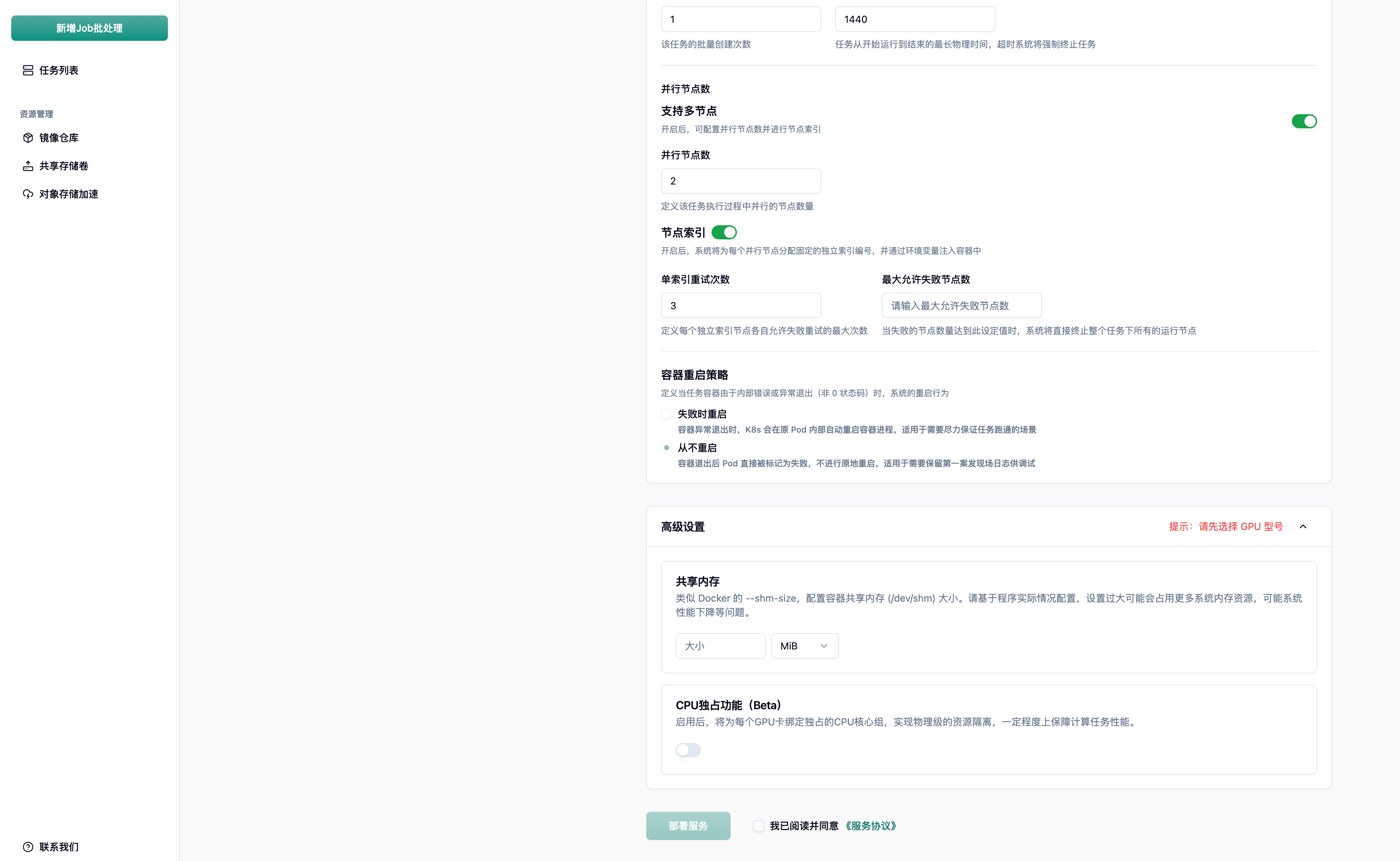
配置项说明:
- 共享内存(shm-size): 配置容器的
/dev/shm大小。在 PyTorch 等深度学习框架中,多进程数据加载(DataLoader 的num_workers > 0)强依赖共享内存。 - CPU 独占功能(Beta): 启用后,系统将为每个 GPU 卡绑定独占的 CPU 核心组,实现物理级的资源隔离,避免”吵闹的邻居”效应。
最佳实践: 运行 PyTorch 训练或涉及大量 IPC(进程间通信)的任务时,务必根据实际情况调大共享内存,否则极易遇到Bus error。对于对计算延迟极度敏感的实时推理任务,建议开启 CPU 独占功能以保障性能稳定性。
四、实战演示:批量并发任务全生命周期
Section titled “四、实战演示:批量并发任务全生命周期”以下基于真实运行数据,展示一次完整的批量并发任务执行过程。
4.1 提交批量任务
Section titled “4.1 提交批量任务”在”任务策略”中将批量创建数设置为 3,使用镜像harbor.suanleme.cn/bala/job-task-demonstration:v1,环境变量设置RUN_SECONDS=60 EXIT_CODE=0,点击”部署服务”提交。
提交后,系统立即在任务列表中生成 3 个独立任务(1-best-practice-batch-demo、2-best-practice-batch-demo、3-best-practice-batch-demo),状态均为等待中,并发调度资源。

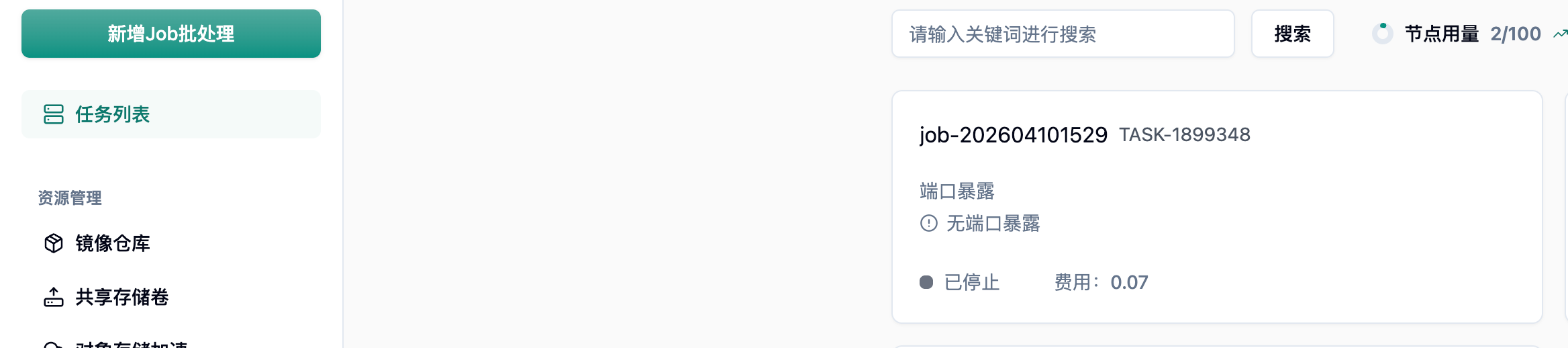
4.2 任务执行完成
Section titled “4.2 任务执行完成”约 2 分钟后(含镜像拉取时间),任务全部执行完成,状态变为已停止,每个任务费用仅 ¥0.07。
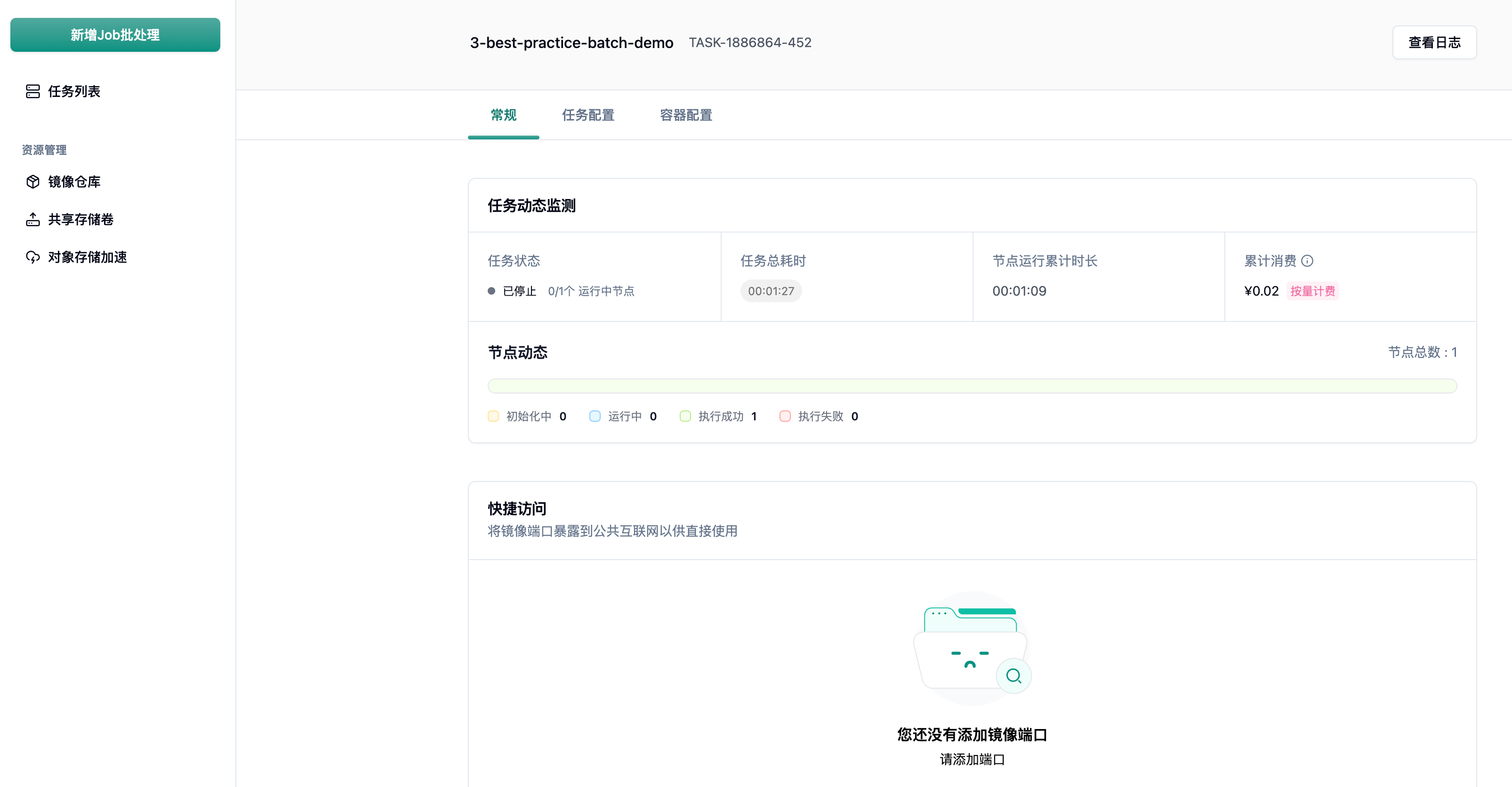
4.3 任务详情监控
Section titled “4.3 任务详情监控”进入任意一个任务的详情页,可以看到完整的执行数据:
- 任务总耗时: 01:27(含镜像拉取时间约 1 分钟)
- 节点运行累计时长: 01:09(实际执行时间,与
RUN_SECONDS=60配置高度吻合) - 累计消费: ¥0.02
- 节点动态: 执行成功 1 个节点
五、任务管理与可观测性
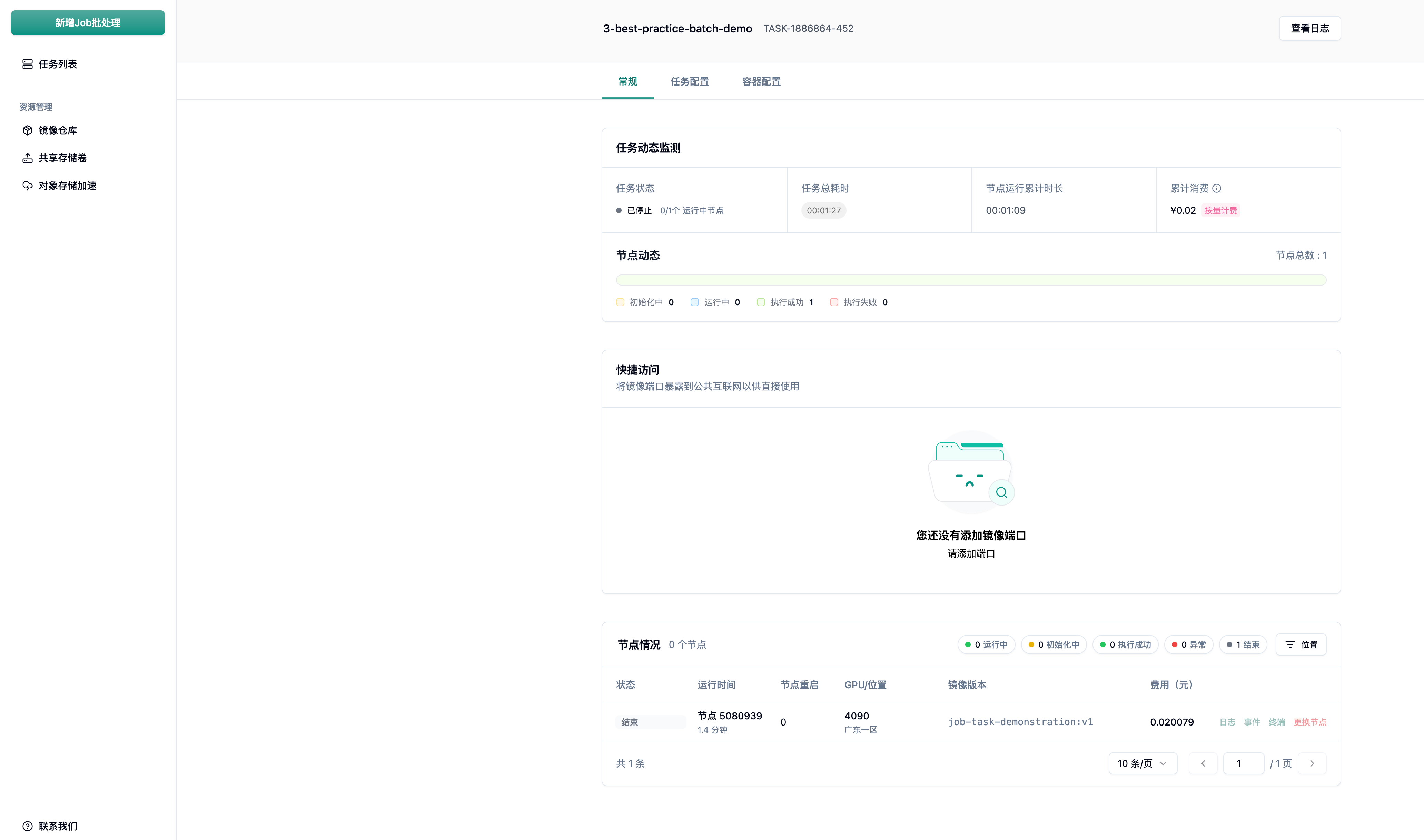
Section titled “五、任务管理与可观测性”5.1 任务列表与详情页
Section titled “5.1 任务列表与详情页”在任务列表中,您可以快速总览所有任务的状态(运行中、等待中、已停止)和累计费用。点击进入任务详情页,可查看更细粒度的信息:
- 常规面板: 展示任务总耗时、节点运行累计时长、当前费用,以及各节点的实时状态进度条。
- 快捷访问: 如果任务配置了 Web 服务或 API 接口,可通过此功能将镜像端口暴露到公共互联网,实现直接访问。
- 任务/容器配置面板: 详细展示该任务创建时的所有配置参数,方便复盘和核对。
5.2 日志查看:容器日志
Section titled “5.2 日志查看:容器日志”在任务详情页点击”查看日志”,即可打开实时日志控制台。平台支持查看标准输出(stdout)和标准错误(stderr),并提供刷新、滚动到底部和下载功能。
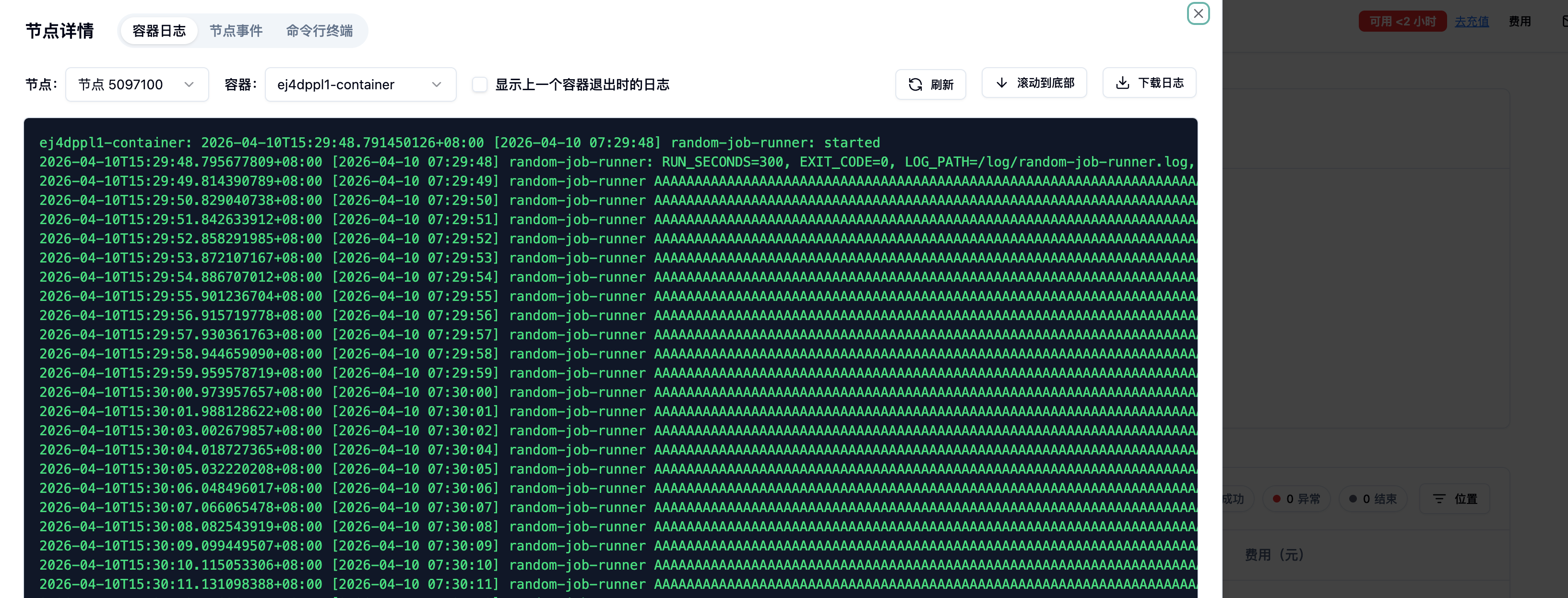
最佳实践: 如果任务已经结束(状态为”已停止”),请务必勾选”显示上一个容器退出时的日志”,否则会看到”暂无日志”。养成输出带有时间戳和关键指标(如 Loss、Accuracy、处理进度)的结构化日志的习惯,便于快速定位问题。
5.3 日志查看:节点事件
Section titled “5.3 日志查看:节点事件”节点事件记录了 Kubernetes 底层的 Pod 事件流,是排查任务启动问题的利器。
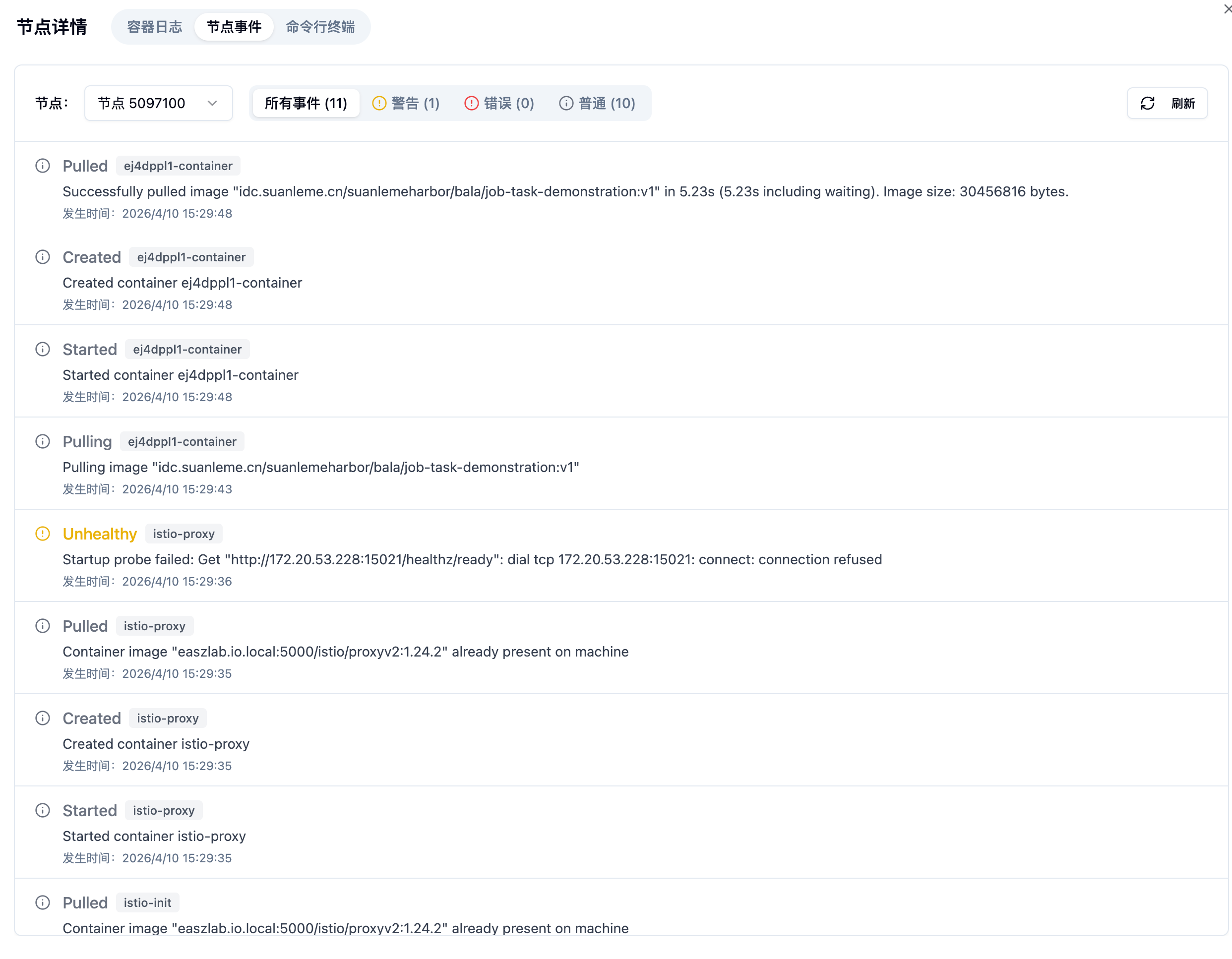
实测事件流清晰记录了完整的生命周期:Pulling(开始拉取镜像)→Pulled(拉取完成,耗时 3.493s)→ Created(容器创建)→Started(容器启动)→ Killing(任务结束,容器停止)。
最佳实践:
当任务长时间处于”初始化中”无法进入”运行中”时,首先查看节点事件中是否存在Warning 类型的事件(如
Unhealthy、Failed),通常可以直接定位到镜像拉取失败、资源不足等根因。
六、关联服务:构建完整的 AI 工作流
Section titled “六、关联服务:构建完整的 AI 工作流”Job 批处理与平台上的其他服务紧密协同,共同构建高效的 AI 基础设施。
6.1 镜像仓库
Section titled “6.1 镜像仓库”镜像仓库用于统一管理您的自定义容器镜像,支持上传私有镜像、管理访问凭证,并显示存储用量和预估费用。
最佳实践: 将您的训练环境(CUDA 版本、Python 依赖、框架版本)打包为私有镜像并推送到平台镜像仓库,既能保障代码安全,又能利用内网高速拉取,大幅缩短任务启动时间。
6.2 共享存储卷
Section titled “6.2 共享存储卷”共享存储卷是 Job 任务之间、以及 Job 与云主机之间共享数据的核心桥梁,支持创建单区域桶和多区域桶,满足不同范围的数据访问需求。
最佳实践: 将训练代码和数据集预先上传到共享存储卷,Job 任务启动后直接挂载读取,避免每次任务启动时重复传输数据。
6.3 对象存储加速
Section titled “6.3 对象存储加速”对象存储加速是提升模型加载速度的”秘密武器”,支持将阿里云 OSS、火山引擎等外部对象存储配置为加速源,通过集群本地缓存实现对外部大文件的极速只读访问。
最佳实践: 将 HuggingFace 等平台上的预训练模型权重同步到对象存储加速桶,Job 任务通过挂载路径直接读取,可将模型加载时间从数十分钟缩短至数秒。注意:存储内容更新后,需要手动点击”回源上游”按钮进行缓存同步。
七、最佳实践总结
Section titled “七、最佳实践总结”场景 | 推荐配置 | 核心收益 |
大规模批量推理 | 批量创建数 + 节点索引 | 并发处理,线性缩短总耗时 |
长时间 AI 训练 | 抢占式计费 + 失败时重启 + Checkpoint | 成本降低 50%~80%,自动容错恢复 |
多进程数据加载 | 调大共享内存(shm-size) | 避免 Bus error,提升 DataLoader 效率 |
快速启动任务 | 使用内网镜像仓库 | 镜像拉取从分钟级降至秒级(实测 3.5s) |
生产环境调试 | 从不重启 + 低重试次数 | 保留完整错误现场,快速定位问题 |
高性能推理服务 | CPU 独占功能(Beta) | 物理级资源隔离,消除性能抖动 |
通过深入理解并应用上述最佳实践,您将能够更从容地应对各种复杂的计算挑战,以最低的成本加速 AI 创新之旅。