
AI 智能体会自主做决策,而工作流的作用,是把这种自主性放进可预期的执行框架里:既保留各步骤内的推理与工具调用,又让整体路径、检查点与节奏可控。
当你需要多个智能体协同完成复杂任务时,真正要拍板的是:哪一种编排模式最贴问题。Anthropic 在与大量团队共建智能体产品的经验里,生产环境绝大多数场景可归入三类:顺序(Sequential)、并行(Parallel)、评估–优化(Evaluator–optimizer)。选错模式,往往直接反映在延迟、token 成本或稳定性上。
下文拆解三类模式各自的适用边界、取舍与组合方式;默认从最简单可行方案起步,再按需升级复杂度。
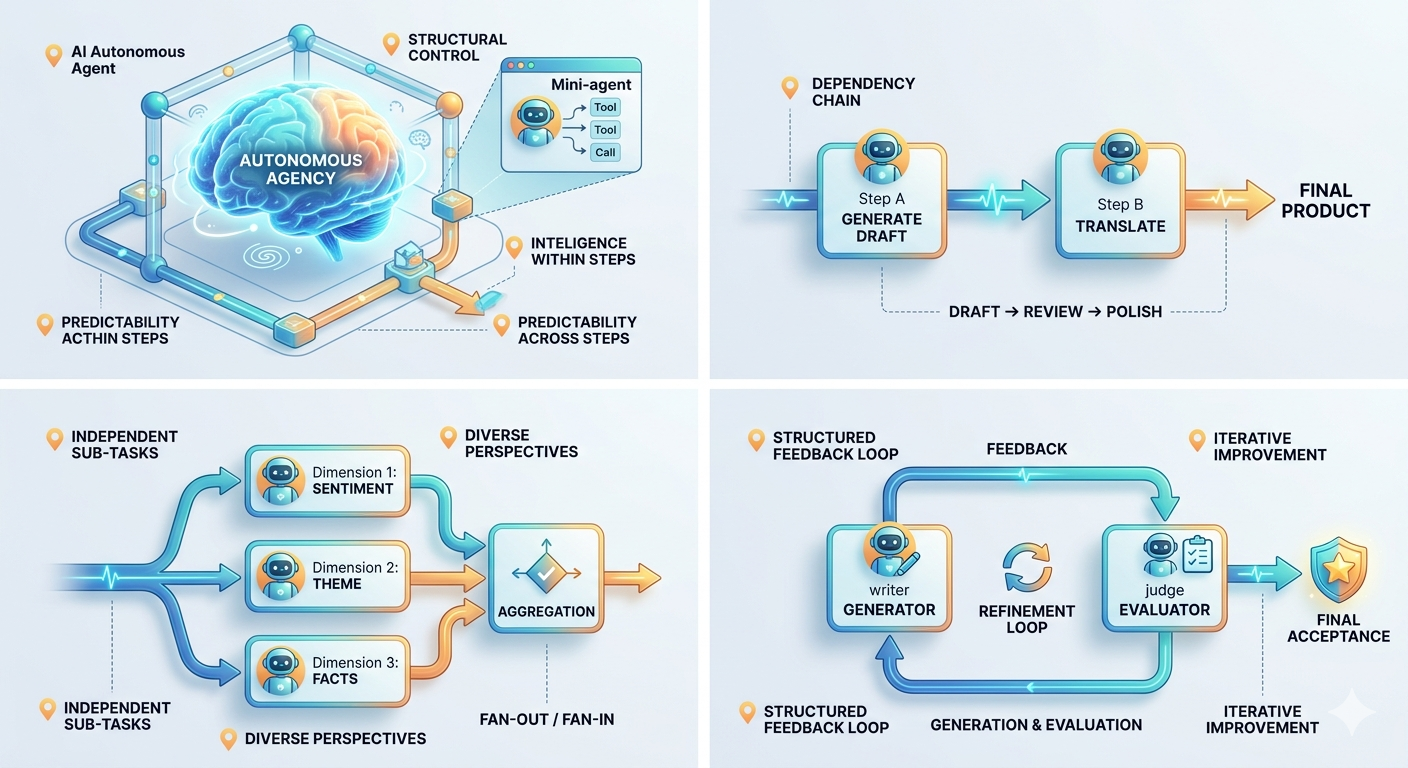
工作流与智能体如何配合
若你带过团队或排过流水线,对工作流不会陌生:流水线上每一站都可以是「会做局部决策的专家」,但整条线的走向在设计阶段就定好了——即便中间包含动态路由、重试等决策。
完全自主的智能体 vs 结构化工作流
- 完全自主的智能体:自己决定用哪些工具、以什么顺序执行、何时结束。
- 工作流:规定宏观流程、检查点与每步边界;步骤内部仍可保留智能体的动态行为。
工作流并不取消智能体的自主性,而是约束自主性落在何处、如何展开。每一步都可以是「会推理、会调工具」的智能体,但跨步骤的编排遵循既定路径;工作流模式提供的是「步骤内的智能 + 步骤间的可预测性」。
三类智能体工作流模式
在生产中,这三类更像可嵌套、可组合的积木,而不是僵死模板:
- 顺序工作流:固定先后顺序执行
- 并行工作流:彼此独立的子任务同时跑多个智能体
- 评估–优化工作流:生成与评估交替,迭代打磨输出质量
解决的问题 | 典型使用场景 | 主要代价 | 主要收益 |
顺序 | 步骤 B 依赖步骤 A 的输出;多阶段管线;草稿–审核–润色 | 每步等待上一步,延迟叠加 | 每步专注一事,往往更易做对 |
并行 | 子任务彼此独立,串行太慢;多维度评估、代码审查、文档分析 | 并发调用更贵;需要明确的聚合策略 | 更快完成;关注点可拆分给不同角色/智能体 |
评估–优化 | 初稿质量不够;需对照明确标准迭代 | token 与轮次倍增;迭代耗时 | 结构化反馈环,可度量地提升终稿质量 |
实践建议:从能解决问题的最简单模式开始;默认倾向顺序。仅当延迟成为瓶颈且子任务真正独立时,再上并行。仅当能量化证明「多轮评估–修改」带来的质量增益值得额外成本时,再上评估–优化环。
顺序工作流
顺序工作流按预定顺序执行:每阶段智能体处理输入、做决策、按需调用工具,再把结果交给下一阶段。输出沿单链路线性传递。
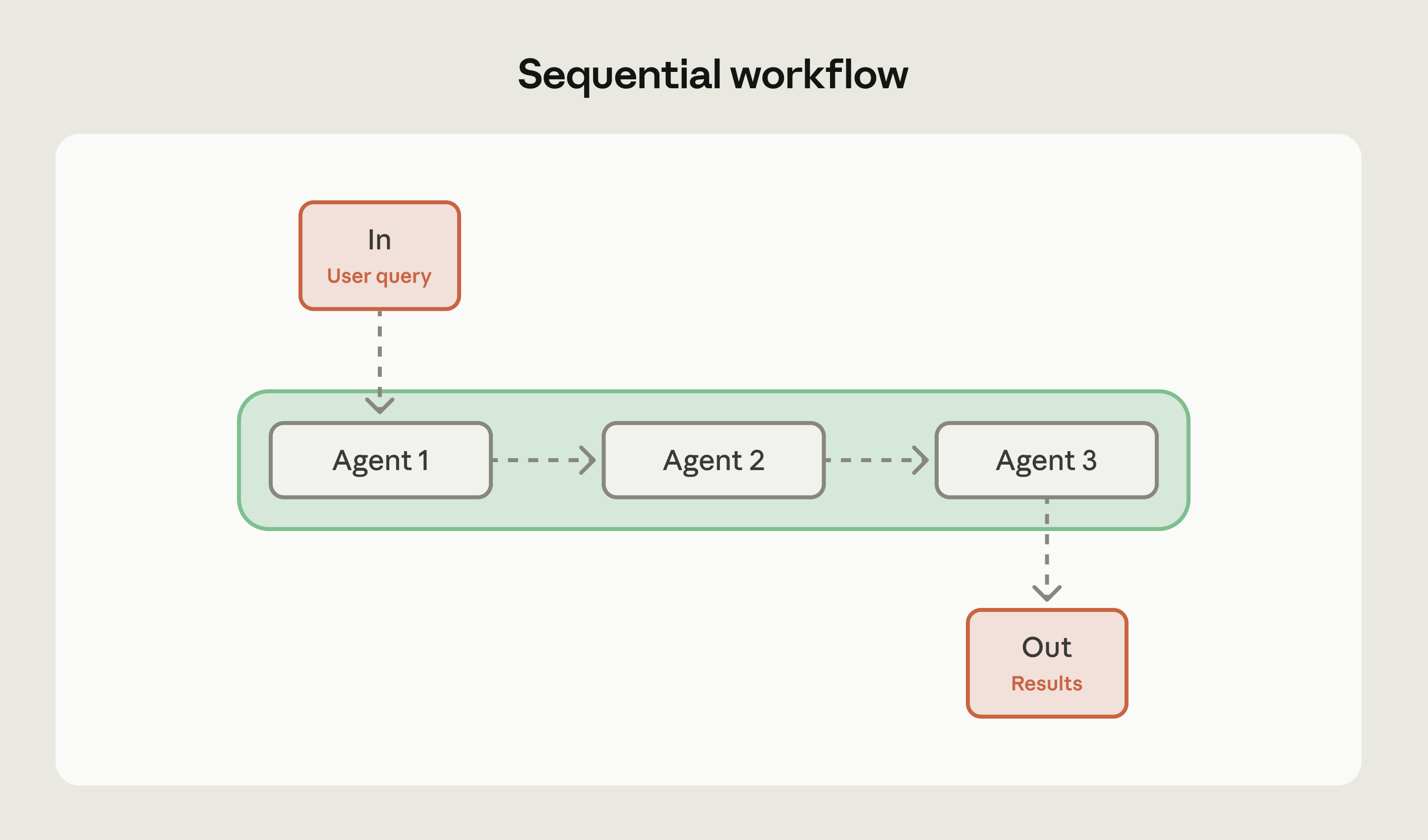
何时适合:任务天然拆成有依赖的多个阶段;数据管线每段增加不同价值;存在无法并行化的先后约束;或「草稿–审核–润色」这类链式迭代。
何时避免:单智能体已能稳定完成端到端任务;或需要的是协作而非「交接棒」式传递。若强行拆成多步却并无真实依赖,只会增加复杂度。
示例:先写营销文案再做多语言翻译;从文档抽取字段 → 按 schema 校验 → 入库。内容安全管线也适合顺序:抽取 → 分类 → 执行规则 → 路由。
技巧:先尝试一个智能体 + 提示词里写清步骤;若质量与稳定性已够,就不必拆工作流。只有单调用靠不住时,再拆成多步编排。
并行工作流
并行工作流把相互独立的任务分给多个智能体同时执行,最后合并或综合结果,类似分布式里的 fan-out / fan-in:多路并行处理,再聚合。
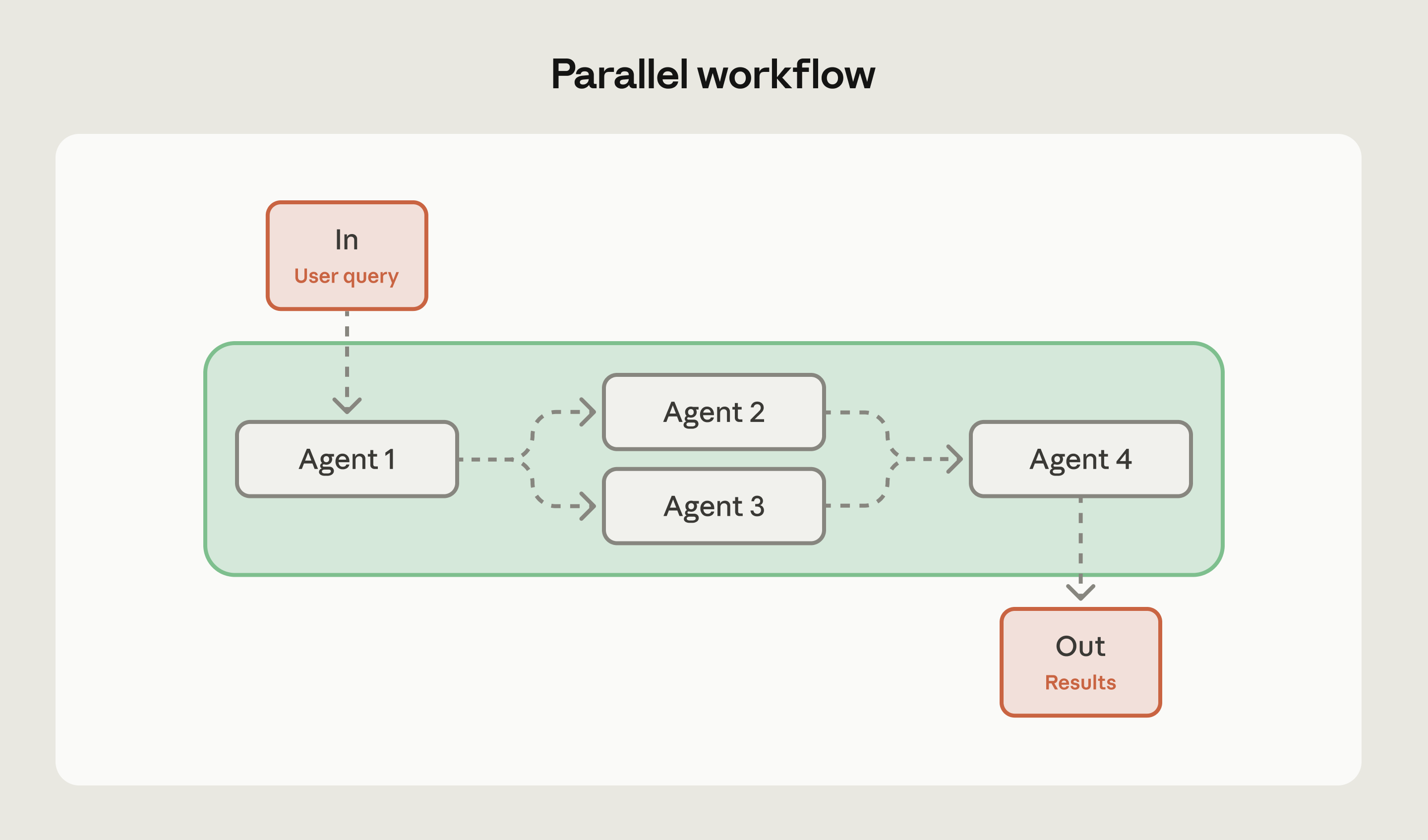
智能体之间通常不互相交接上下文,而是各自产出对整体任务有贡献的结果。
何时适合:可切成独立子任务且并行能明显缩短 wall-clock;需要对同一问题取多视角(如一路处理查询、另一路做安全筛查);多维度打分或「多评审员」式代码审查。
何时避免:后续步骤必须累积使用前序全部上下文;API 配额或成本不允许并发;不同智能体结论互相矛盾且没有可信的仲裁策略;聚合逻辑过于复杂反而拉低质量。
示例:自动化评测(每路检查不同质量维度);代码审查(不同智能体盯不同漏洞类别);文档分析并行做主题抽取、情感分析、事实核对,再汇总。
技巧:在实现并行之前先设计好聚合策略:多数票?置信度加权?还是听最专精的一路?避免收上来一堆冲突结论却无法落地。
评估–优化工作流
评估–优化由两个角色(或两类提示)循环配合:生成产出内容,评估按明确标准打分或列问题,生成方再据反馈修改;直到达到质量阈值或达到最大迭代次数。
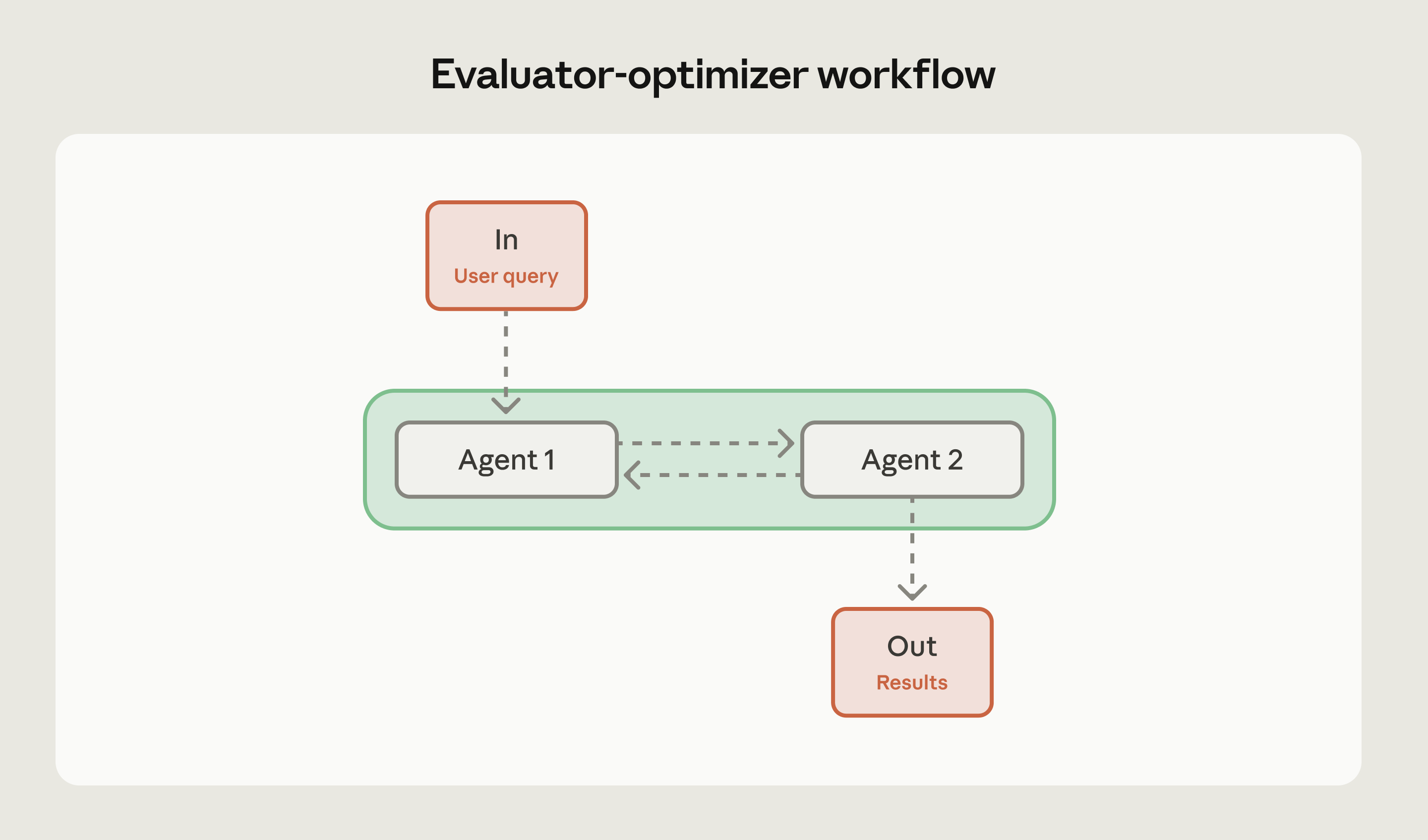
生成与评估是两类认知任务;拆开能让生成专注「写出来」,评估专注「按同一套尺子量」。
何时适合:有可被 AI 稳定执行的明确质量标准,且初稿到终稿的差距值得多付 token 与时间。例如:按安全/性能/风格规范写代码;对外沟通需兼顾语气与合规;任何「一稿经常不达标」的场景。
何时避免:首稿已满足需求(多轮纯属浪费);强实时、必须立即响应;任务极简单(如基础分类);评估标准过于主观、模型无法一致适用;已有确定性工具(如 linter)能替代「模型当裁判」;或资源约束大于质量收益。
示例:生成 API 文档并由评估方对照代码检查完整性与准确性;生成客服邮件并由评估方检查语气与政策合规;写 SQL 并由评估方看效率与注入风险。
技巧:迭代前定好停止条件:最大轮数、明确的质量阈值。否则容易陷入「评估总挑小毛病、生成总微调」但质量早已平台化的昂贵循环;要事先定义「足够好」。
如何选择合适的工作流模式
取决于任务结构、质量目标与资源上限。决策前可先问:
- 单智能体一次调用能否搞定? 能则不必上复杂工作流。
- 是否存在清晰的顺序依赖? 有则优先考虑顺序。
- 子任务能否独立并行,且更快完成有价值? 再考虑并行。
- 结构化迭代能否带来可度量的质量提升? 再考虑评估–优化。
选定模式后,还应明确:
- 失败处理:每步的降级、重试与超时。
- 延迟与成本:决定能开多少并行、允许多少轮迭代。
- 是否真变好:用「单智能体基线」对比,避免为架构而架构。
组合使用:三类模式可嵌套。例如评估–优化里,评估阶段可并行多路评估不同维度;顺序管线中某一阶段可对内并行多个独立操作。原则是:复杂度对齐真实需求——能并行带来的收益明确再上并行;能证明迭代提质再上评估–优化。
审慎演进工作流
建议路径:从最简单、能跑通的形态开始。顺序能覆盖就不必并行;首稿够好就不必加评估–优化环。三类模式提供了升级路径:顺序瓶颈处可局部并行;质量要求收紧时可加评估;模块之间可替换而非全盘重写。
更完整的架构模式与实现框架可参考 Anthropic 白皮书:Building effective AI agents: architecture patterns and implementation frameworks(与博客文末引用一致)。
本文导读基于 Claude 官方博文整理,便于中文读者快速对照三类工作流在生产中的取舍与落地要点。